개요
정규표현식으로 자연어 처리를 할 때에 있던 일이다. 분명 한글인데, 인식을 못하는 경우가 있다. 인코딩 문제가 아닐까 싶다. 정확한 원인 규명은 못했지만 내 나름대로 해결한 문제를 기록해본다.
문제점
내가 정규표현식을 통해 한글을 검색하려 했었는데, None을 뱉어내는 경우가 있어서 이상하게 여겨 한번 테스트를 해봤다.
subs=[
'대법원 2016. 10. 13. 선고 2016두42449 판결',
'대법원 2017. 11. 23. 선고 2015다1017, 1024, 1031, 1048 판결'
]
com=re.compile(r"[가-힣]")
for sub in subs:
search_word=com.search(sub)
print(f'{sub}에서 검색 결과 : {search_word}')
# 출력 결과
# 대법원 2016. 10. 13. 선고 2016두42449 판결에서 검색 결과 : None
# 대법원 2017. 11. 23. 선고 2015다1017, 1024, 1031, 1048 판결에서 검색 결과 : <re.Match object; span=(0, 3), match='대법원'>??? 이게 무슨 일이지? subs 안에 들어있는 두 문장은 영락없는 한글인데 하나는 되고, 다른 하나는 왜 안될까?
나는 내 정규식이 틀렸나 싶어서 https://regexr.com/ 이 사이트에서 확인을 해보았다.

??? 왜 또 안될까? 어이가 없어서 저 안되는 부분을 똑같이 복붙해봤다.

이번엔 위에껀 잡히는데 밑에껀 또 안잡힌다;;;; 뭔 차이가 있을까 싶어서 밑에 결과를 살펴보니 알 수 있었다.


뭔 차이인지 알겠는가? 보시다시피 code가 다른 것을 알 수 있다! 인코딩이 잘못된 것 같다는 생각이 들었다...
그리고 마우스를 가져다 대면,

저렇게 나뉘어지는 것을 보고 인코딩이 잘못되었다는 것을 확신할 수 있다.
# 원본 텍스트
original='대법원 2016. 10. 13. 선고 2016두42449 판결'
# 그대로 직접 타이핑한 텍스트
copy='대법원 2016. 10. 13. 선고 2016두42449 판결'
print(len(original),len(copy))
# 출력 결과
# 47, 34심지어 길이도 달랐다. 그러니 내가 단어를 찾을 수가 없었던 것이었다... 이런걸 어떻게 사용해야할까...
내가 생각한 해결법
어차피 정규식도 유니코드로 찾아내는 거니까 코드 번호로 명시해주면 찾아지지 않을까? 라는 생각을 했다. 그래서 실제로 시도한 결과..
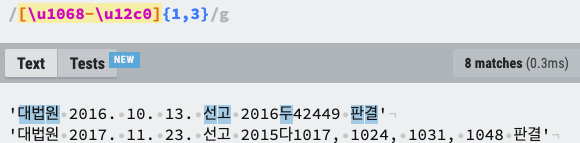

잘 잡혔다! 대충 어림잡아 4200~4800사이로 바꿔서 \u(16진수) 이와 같이 넣어주었다.
21/04/01 업데이트 내용.
이후에 업무를 하다가, 윈도우에서 만든 텍스트 파일을 mac에서 사용하려니 문제가 생겼다. cp949로 인코딩해서 내용물을 활용한 것 까지는 좋았다. 하지만 내가 코드 중에, 파일 제목을 변수에 담아서 내용과 비교를 하는 로직을 짠 적이 있었다. 또 찾을 수 없다고 뜨길래 확인해보니 위의 상황들과 같았다.
import glob
file_list=glob.glob('./data/*.txt')
for file in file_list:
title=file.split('/')[2]
load_file(title)
...
# 결과
KeyError: 'title'
오잉? 분명 있는 것인데 왜 없다고 하지??? 그래도 이번에 문제점은 확실히 알았다(사실 몇시간 끙끙 앓았음...). 내용은 파이썬 내부함수로 파일을 읽으면서 인코딩하면 되지만, 파일 제목은 인코딩이 되지 않는다는 점이다. 그래서 이것을 어떻게 다시 돌려놓았는가 함은...!!!
from unicodedata import normalize
import glob
# 여기서 파일 명을 들고오면서 인코딩이 안된 것을 가지고 사용하다보니 에러가 난것이다..
file_list=glob.glob('./data/*.txt')
for file in file_list:
title=file.split('/')[2]
title = normalize('NFC', title)
load_file(title)
...
from unicodedata import normalize 를 임포트 해와서!!title = normalize('NFC', title) NFC 로 맹글어주면 된닷 ㅎㅎ
정말 간단했다.. 코드 몇줄로 끝나다니 살짝 허무하긴 했는데, 해결되서 다행이다 😩
여기서 NFC가 뭔지 궁금하신 분들은 이 곳 에서 설명이 잘 되있으니 참고하시면 될 것 같다!
마무리
DB에서 데이터를 가져오다보니 어쩌다 이렇게까지 하게 되었는지 모르겠지만, 원인이 정확히 어디서부터 그렇게 된지 찾기가 쉽지가 않다. window와 mac 사이를 파일로 왔다갔다해서 그런가 인코딩이 엉킨거 같기도 하다. 어떻게 통일화할지는 아직 생각을 못해봤는데, 그것도 언젠가 찾아서 하게 되면 안까먹게 포스팅 해야겠다 😋
reference
'python > 자연어처리' 카테고리의 다른 글
| [자연어처리 입문] 2. 언어 모델(Language Model) (0) | 2021.04.13 |
|---|---|
| [자연어 처리 입문] 1. 텍스트 전처리 (0) | 2021.04.11 |
| [Python] Soynlp 기반 미등록단어 찾아보기 (with mecab) (0) | 2021.03.11 |
| [Python] Pandas를 이용하여 데이터를 다뤄보자. (0) | 2021.03.08 |
| [Python] 정규표현식 (0) | 2021.02.24 |