맨 아랫줄은 mysql setting 값들을 파일로 적용시키기 위함이다. 아래 사진 참고.
출처 : https://hub.docker.com/_/mysql
2. DB 생성 확인
~ ❯ docker exec -it drf-example /bin/bash
root@937526738ea0:/# mysql -u root -ptest1234
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.38-log MySQL Community Server (GPL)
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| test |
+--------------------+
5 rows in set (0.07 sec)
mysql>
~/drf_example ❯ python manage.py runserver
...
django.db.utils.OperationalError: (2002, "Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)")
뜬금없이 socket 파일을 못 찾는다 ㅇㅈㄹ 너무 화가 남.... 이거 때문에 조금 시간을 허비했다....
구글링 결과 알고 보니 django settings 파일에 db host 값을 localhost라 하면 django가 db 통신을 tcp로 하는 게 아닌 소켓으로 해버린단다...
프로그래밍 공부를 하는 사람들이면 얕은 복사, 깊은 복사에 대해 들은 적이 있을 것이다. 나도 그랬었고 얕은 복사는 주소 값을 복사하여 하나가 변경되면 같이 변경되는 것으로 대강 알고 있었다. 이것이 중요하다고 하는 것을 많이 봤었는데, 나는 역시 직접 겪기 전까지 모르는 것 같다. 그래서인지 업무 중에 기어코 일을 내고 말았다.
🚨 상황
어떤 데이터를 보내는데 필요없는 키워드를 걸러주기 위해 filter keyword 모듈을 만들어서 키워드 필터링을 하고 있었다. 단순히 검색 단어에 따라 등록해둔 필터링할 키워드를 가져와서 공통 필터링할 키워드와 합쳐서 키워드를 걸러주는 로직이었다. 하지만 처음엔 검색 키워드에 필터링 키워드가 지워져서 정상적으로 작동했는데, 가면 갈수록 검색 키워드에 상관없이 등록해뒀던 모든 키워드로 필터링이 되는 것이다. 코드로 보면 더 이해가 빠르다.
FILTER_KEYWORD를 전역 변수로 선언하고, 모든 검색어에도 적용되게 하기 위해 공통 필터 키워드를 사전에 추가하고, 사전에서 특정 검색 단어의 필터키워드와 합쳐서 리턴하는 함수를 만들었다.
문제는 리턴 값을 보면 알 수 있다. set은 mutable 객체기 때문에, 위 예제와 처럼 FILTER_KEYWORD의 공통 set을 단순 대입하는 것과 같이 얕은 복사로는 filter_keywords의 값이 변경되면 FILTER_KEYWORD의 공통 set의 값도 같은 값으로 업데이트 되어버리는 것이다.
이 부분은 마지막 print 부분을 보면 쉽게 이해가 가능하다. 결과적으로 변하지 않아야 할 FILTER_KEYWORD['공통'] 값이 바뀌어 버린 것이다.😱
내부의 리스트들은 주소값이 여전히 같은 것을 알 수 있다. 이 말은 내부 리스트까지는 복사(다른 주소 값으로 할당)가 되지 않았다는 것이다. 정리하면, 딕셔너리나 리스트처럼 내부 요소에도 또 list, set, dict를 가질 수 있는 자료형들은 .copy() 통해서는 하위의 데이터까지는 복사가 되지 않는다는 것이다. (list slicing을 이용한 경우에도 동일하다.)
deepcopy()를 사용하니 b의 값만 바뀐 것을 알 수 있고, 하위 리스트의 주소 값을 비교해봐도 달라진 것을 볼 수 있다. 이제야 제대로 값만 복사된 것이다.
오늘의 교훈 : 변하지 않아야 하는 변수는 꼭!! immutable 객체(tuple, frozenset 등)로 만들어주자!! 다른 분들은 저처럼 의도하지 않은 결과를 얻는 일이 없도록 바래요...😢
👋 마무리
나는 대충이라도 알고있던 개념을 실제 상황에서 만나보니 전혀 신경 쓰지 못하고, 대응하지 못했다. 이거 때문에 내가 아닌 다른 분께서 에러 잡아내느라 늦게 퇴근하셨다고 한다. 그러고 이런 에러가 있었다고 말씀해주셨었다... 진짜 듣는 순간 수치플...😵 내가 짠 코드에서 결함이 발견될 때가 제일 현타 온다. 내가 이것밖에 못하나.. 이런 생각이 들면서 😭
그래도 나를 생각해서 말하지말까 하시다가 솔직한 피드백을 주신 것에 감사했다. 덕분에 내가 제대로 알고 다음부터 더욱 신경 써서 코드를 짜지 않을까 싶다. 그래도 앞으로 이런 일이 생기지 않도록 배운 내용들을 토이 프로젝트에 적용시켜 보면서 실패를 겪어 봐야겠다는 생각이 들었다. 배운 것을 얕게만 알고 있지 말고 내 것으로 만들 수 있도록 노력하자..💪
하지만, 멀티 프로세싱을 이용하면 메모리를 많이 잡아먹는 문제가 생긴다. 그래서 다른 방법을 강구하기 시작했다. 그래서 찾은 방법은 바로 . . . . 동시성 프로그래밍을 이용한 비동기처리다!!!! 하지만 우선 이녀석이 무엇인지를 알고 써야 좋지 않겠는가..? 간략하게 사전지식을 알아보고 넘어가자😆
내가 이해한 결과로는 동시성은 주어진 과제를 멀티 쓰레드나 비동기 통신을 이용하여 효율적으로 처리하여 대기시간을 줄여 결과적으로 전체 실행 시간을 줄여 병렬적으로 처리되는 듯한 효과를 낼 수 있고, 병렬성은 멀티 프로세싱을 활용하여 각각의 프로세스들이 독립적으로 과제를 처리하므로 전체 실행 시간을 줄인다.
여기서 중요한 것은 위의 말에는 전제조건이 있다는 것이다. 동시성은 각각의 프로세스들이 독립적으로 자원을 가지고 처리하는 것이 아니다보니, CPU bound 작업(네트워크나 파일에 엑세스하는 작업 없이 계산 작업 등)에서는 좋은 효과를 볼 수가 없다. 즉 외부 I/O 작업을 진행할 때에 발생하는 대기 시간을 줄여 동시적으로 처리하는 것 뿐이지, 외부가 아닌 컴퓨터의 연산작업을 진행할 때에는 좋은 효과를 볼 수 없다. 글에서 말하기로는 프로그램의 속도를 결정짓는 자원이 CPU이기 때문이라고 한다.
그렇다고 마냥 멀티프로세싱이 좋은가? 프로세스들을 여러개를 생성한다는 것은 곧 새로운 인터프리터를 띄우는 것이므로, 하나의 프로세스에서 여러 쓰레드를 생성하는 것보다는 훨씬 무겁고 제한적이며 어려움도 많을 것이기 때문이다.
결론은 상황에 맞게 잘 선택해서 쓴다면 좋은 효과를 얻을 수 있을 것이다. 🤩
그럼 일단 내 task를 생각해보자. 다른 사이트에서 request를 보내 response로 받은 데이터를 사용할 것이기 때문에, 내 컴퓨터가 아닌 외부 서버에서 하는 작업이니 I/O 작업임을 알 수 있다 ! 즉, 굳이 멀티프로세싱을 사용하지 않아도 동시성을 이용해 해결이 가능하다 !
python에서는 GIL(Global interpreter Lock) 때문에 메인쓰레드에서 모든 연산을 처리하기에 Threading을 사용한 동시성 제어는 느리다고 한다. 그리고 우리는 HTTP 통신 대기와 같은 Blocking IO의 대기시간을 줄여 보고자, 쉽게 사용할 수 있는 asyncio 택할 수 있다.
자, 그러면 python에서 지원하는 Asyncio에 대해 알아보자!🔜
Asyncio
시작하기에 앞서 파이썬은 공식문서가 잘 되어 있기에 읽으면서 내가 이해한 부분을 적은 것이라 틀린 것이 있을 수 있다. 그렇기에 잘못된 것이 있거나 수정해야할 부분이 있으면 언제든지 댓글 달아주시면 감사하겠습니다,,
함수를 만들어줄 때 앞에 async를 적어준다는 뜻은, 해당 함수를 코루틴 객체로 선언한다는 의미임을 알 수 있다. 평소 함수처럼 호출하면 실행되지 않고, 객체를 반환하는 것을 위 예제를 통해 확인할 수 있다.
즉, 코루틴은 asyncio 프로그램을 실행할 때 실행될 객체라고 생각하는게 편할 것 같다. 그리고 이런 코루틴이 실행되도록 예약을 해주는 것이 태스크이다. 예제를 통해 태스크를 만드는 것을 살펴보자
import asyncio
async def coro():
...
# In Python 3.7+
task = asyncio.create_task(coro())
...
# This works in all Python versions but is less readable
task = asyncio.ensure_future(coro())
...
coro 라는 코루틴을 asyncio.create_task()를 통해 태스크로 만들어서 실행되는 것을 예약할 수 있다. 아직은 실행되는 방법도 모르는데, 이런 예약한다는 말이 뭔소리인가 싶을 텐데 나중에 차차 설명하겠다. 우선은 이정도로 넘어가자.
➕ awaitable 이란?
객체가 await 표현식에서 사용될 수 있을 때 어웨이터블 객체라고 말합니다. 많은 asyncio API는 어웨이터블을 받아들이도록 설계되어있다고 말한다. 어웨이터블 객체에는 세 가지 주요 유형이 있다: 코루틴, 태스크 및 퓨처(future)
쉽게 말해 await 사용가능한 객체들을 말하는 것 같다. 그럼 await는 뭘까? awaitable 객체 안에서 await가 나오면 그 부분은 실행될 때까지 기다리고 다음 코루틴을 실행시킨다고 이해했다.
위 예제처럼 실행시키는 건 간단하다. 하나의 코루틴 객체 main()을 asyncio.run()을 통해 실행시킨다. 이 실행시키는 run()에 대해서 조금 더 자세히 알아보자. 우선 공식 문서에는 다음과 같이 적혀있다.
이 함수는 전달된 코루틴을 실행하고, asyncio 이벤트 루프와 비동기 제너레이터의 파이널리제이션과 스레드 풀 닫기를 관리합니다. 다른 asyncio 이벤트 루프가 같은 스레드에서 실행 중일 때, 이 함수를 호출할 수 없습니다. 이 함수는 항상 새 이벤트 루프를 만들고 끝에 이벤트 루프를 닫습니다. asyncio 프로그램의 메인 진입 지점으로 사용해야 하고, 이상적으로는 한 번만 호출해야 합니다.
눈에 띄는 부분만 보자면, 메인 진입 지점으로 사용해야 하고, 이상적으로는 한 번만 호출해야 한다는 것을 명심하자. 즉, 다른 코루틴들을 실행하는 main() 코루틴만을 실행시키면 될 것 같다.
3. 동시에 태스크 실행하기
실제로 쓸만하려면 동시에 여러 태스크를 실행시킬 수 있어야지 않겠는가? 그것을 위한 asyncio.gather() 함수를 예제를 통해 이제껏 읽은 정보들을 종합적으로 사용한 대략적인 흐름을 살펴보자.
아 잠깐, 일단 asyncio.gather() 함수에 대한 설명을 간단히 알아보자. 들어오는 인풋이 코루틴이면 자동으로 태스크로 예약을 시켜준다. 그리고 모든 awaitable이 성공적으로 완료되면, 결과는 반환된 값들이 합쳐진 리스트이다. 결과값의 순서는 awaitable의 순서와 일치한다.
즉, 코루틴을 인풋으로 넣어주면 그것을 알아서 태스크로 등록해준다는 것이다. 그리고 각 코루틴들이 전부 다 실행될 때까지 기다리고 전부 완료시 결과값을 리스트로 반환해주는 아주 기특한 method임을 알 수 있다.
import asyncio
async def factorial(name, number):
f = 1
for i in range(2, number + 1):
print(f"Task {name}: Compute factorial({number}), currently i={i}...")
await asyncio.sleep(1)
f *= i
print(f"Task {name}: factorial({number}) = {f}")
return f
async def main():
# Schedule three calls *concurrently*:
L = await asyncio.gather(
factorial("A", 2),
factorial("B", 3),
factorial("C", 4),
)
print(L)
asyncio.run(main())
# Expected output:
#
# Task A: Compute factorial(2), currently i=2...
# Task B: Compute factorial(3), currently i=2...
# Task C: Compute factorial(4), currently i=2...
# Task A: factorial(2) = 2
# Task B: Compute factorial(3), currently i=3...
# Task C: Compute factorial(4), currently i=3...
# Task B: factorial(3) = 6
# Task C: Compute factorial(4), currently i=4...
# Task C: factorial(4) = 24
# [2, 6, 24]
일단 제일 먼저 asyncio.run를 통해 하나의 event loop를 만들고, main() 코루틴을 실행시킨다. main()안에 있는 asyncio.gather가 인풋으로 awaitable 코루틴인 factorial 들을 받는다. 그러면 자동으로 task로 schedule 되고 들어온 순서대로 실행된다. 이 과정을 내가 생각한데로 그려보면 아래 그림과 같다. (실제와 다를 수 있으니 틀리면 말해주세요..)
즉, 제일 처음 코루틴을 실행시키고 await를 만나면 그 코루틴의 상태를 (위 그림에서 waiting)변화시켜놓고 다음 코루틴을 실행시킨다. 계속 반복하다가, 끝에 다다르면 다시 처음으로 돌아가서 await가 아닌 상태 (위 그림에서 ready)인 코루틴이 있으면 다시 나머지를 실행시킨다. 그리고 그 코루틴이 return까지 실행되면 완료되었기에 값을 리스트에 넣어놓고, 전부 완료될 때까지 앞서 말한 과정들을 계속 반복한다.
이 예제에서는 await가 걸린 부분이 asyncio.sleep(1) 으로 되어있어서 감이 안 올 수 있다. 우리의 목표는 scraping의 속도를 올리기위해 이것을 사용해보려는데 어떻게 적용시킬까?
asyncio scraping에 적용시키기
조금만 생각해보면 간단할 수 있다. scraping을 할 때에 시간이 오래걸리는 이유는 request를 보내고 response를 받는 데까지의 대기시간이 있기 때문이다. 그 대기시간은 우리의 컴퓨터에서 cpu 연산과 같이 작업을 하느라 걸리는 시간이 아니기 때문에 외부 서버가 처리하고 응답을 줄 때까지 그냥 기다리는 것과 같다. 즉 asyncio.sleep()와 같다는 것이다. 이 부분을 request.get(url)로 바꾸면 어떨까? 우리가 원하는 데로 이루어지지 않을까??
그래서 간단하게 네이버와 다음 홈페이지 html을 받아오는 것을 해보려고한다.
1. resquests 모듈로 될까?
async def get_request_data(url):
response = await requests.get(url)
print(response)
content = response.text
return content
async def main(url_list):
input_coroutines = [get_request_data(url_) for url_ in url_list]
res = await asyncio.gather(*input_coroutines)
return res
if __name__ == '__main__':
url_list = ['https://www.naver.com/','https://www.daum.net/']
res = asyncio.run(main(url_list))
print(res)
하지만 실행시켜보면 바로 다음과 같은 error를 뱉는다.
File "asyncio_test_blog.py", line 15, in get_request_data
response = await requests.get(url)
TypeError: object Response can't be used in 'await' expression
내용을 보면 await를 사용할 수 없다고 하는데, asyncio를 사용할 때에는 requests 모듈은 지원?호환?되지 않는다고 어딘가에서 봤던거 같다.
(출처 남길랬는데 다시 찾으려니 못 찾겠음...)
그래도 일단 비교를 위해 네이버와 다음 페이지를 가져오는 시간을 측정해 놓자. request.get으로 두 페이지를 가져오는데 걸리는 시간은 총 0.15484380722045898 sec 정도 걸린다.
그럼 asyncio는 어떻게 해야하나..? asyncio와 찰떡인 라이브러리가 당근 존재한다. "aiohttp"를 이용하면 쉽게 가능하다 !
2. aiohttp 사용하기!
async def get_data(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
content = await response.text()
print(response)
return content
async def main(url_list):
input_coroutines = [get_data(url_) for url_ in url_list]
res = await asyncio.gather(*input_coroutines)
return res
if __name__ == '__main__':
url_list = ['https://www.naver.com/','https://www.daum.net/']
result = asyncio.run(main(url_list))
url들을 하나씩 꺼내서 reponse를 얻어오는 코루틴으로 만들어주고, 그것을 asyncio.gather의 인풋으로 넣어줘서 task로 만들어 모두 끝날 때까지 실행시킨 결과를 list로 받는다. 여기서 중요한 점은 순서가 응답이 빨리 온 순서라서 url 순서와는 다를 수 있다.
실행 결과 잘 작동한다! 심지어 걸린 시간은 9.5367431640625e-07 sec 정도 걸렸다. 0.0000009초정도,, 거의 뭐.. 0초에 가까운 수치이다. 이렇게 빠르게 request를 보내어 결과값을 받아올 수 있다는 것을 알게 되었다. 페이지를 가져오고 나머지 파싱하고 원하는 데이터를 가져오는 로직만 추가하면 빠르게 scraping이 가능할 것 같다!
마무리
asyncio를 통해 python 공식문서를 뒤져가면서 이 모듈에 대해 공부하다보니 이것들 뿐만아니라, 몰라서 못쓰고 있던 좋은 기능들이 많겠구나 라는 생각이 들었다. 지금까지는 매번 알던 것들로 기능구현하기에 급급했는데, 성능이나 효율성을 높이기 위해 투자할 시간과 노력은 더 더욱 필요한 것 같다. 시간과 노력이 많이 들더라도 인내심을 가지고 내가 만들었던 기능들을 성능을 향상시키는 고민과 행동들을 해보는 것이 내 성장에 많이 도움될 것 같음을 느꼈다.
아참, scarping에 asyncio를 이용해 시간을 단축시키는 것은 좋지만, 반대로 생각해보면 동일한 곳에서 짧은 시간동안 많은 request를 날리기 때문에 server 측에서 공격으로 인식하여 IP block이나 등등 제재가 가해질 수 있기 때문에 조심해서 사용하길 바란다 ㅎㅎ.. 사실 scraping 보다 다른 곳에 더 많이 사용되지 않을까 싶다..?
저번 글에서 머신러닝을 간략하게 살펴보았고, 딥러닝을 이해하기 위한 요소들에 대해 좀 더 자세하게 알아보도록 하자.
1. 선형 회귀(Linear Regression)
딥러닝을 이해하기 위해서는 선형 회귀(Linear Regression)와 로지스틱 회귀(Logistic Regression)를 이해할 필요가 있다. 뿐만 아니라 머신 러닝에서 쓰이는 용어인 가설(Hypothesis), 손실 함수(Loss Function) 그리고 경사 하강법(Gradient Descent)에 대한 개념과 선형 회귀에 대해서 이해합니다.
1.1 선형 회귀란?
시험 공부하는 시간을 늘리면 늘릴 수록 성적이 잘 나온다. 하루에 걷는 횟수를 늘릴 수록, 몸무게는 줄어든다. 집의 평수가 큰 수록, 집의 매매 가격은 비싼 경향이 있다. 이는 수학적으로 생각해보면 어떤 요이의 수치에 따라서 특정 요인의 수치가 영향을 받고 있다고 말할 수 있다. 좀 더 수학적인 표현을 써보면 어떤 변수의 값에 따라 특정 변수의 값이 영향을 받고 있다고 볼 수 있다.
이와 같이 다른 변수의 값을 변하게하는 변수를 x, 변수 x에 의해서 값이 종속적으로 변하는 변수 y라고 해봅시다. 선형 회귀는 한 개 이상의 독립 변수 X와 종속 변수 y의 선형 관계를 모델링한다. 만약 독립 변수 x가 1개라면 단순 선형 회귀라고 한다.
1️⃣ 단순 선형 회귀 분석(Simple Linear Regression Analysis)
$y = Wx + b$
위 수식은 단순 선형 회귀의 수식을 보여준다. 여기서 독립 변수 x와 곱해지는 값 W를 머신 러닝에서는 가중치(weight), 별도로 더해지는 값 b를 편향(bias)이라고 한다. 직선의 방정식에서 각각 직선의 기울기와 절편을 의미한다. W와 B가 없이 y와 x란 수식은 y는 x와 같다는 하나의 식밖에 표현하지 못하므로, W와 b의 값을 적절히 찾아내면 x와 y의 관계를 적절히 모델링한 것이 된다.
2️⃣ 다중 선형 회귀 분석(Multiple Linear Regression Analysis)
$y = W_1x_1 + W_2x_2 + W_3x_3 + ... + W_nx_n + b$
잘 생각해보면 집의 매매 가격은 단순히 집의 평수가 크다고 결정되는 것이 아니라 집의 층 수, 방의 개수, 지하철 역과의 거리와도 영향이 있는 것 같다. 이제 이러한 다수의 요소를 가지고 집의 매매 가격을 예측해보고 싶다. y는 여전히 1개이지만 이제 x는 1개가 아니라 여러 개가 되었다. 이와 같이 여러 독립 변수들을 가지고 회귀 분석을 하는 것을 다중 선형 회귀 분석이라 한다.
1.2 가설(Hypothesis) 세우기
단순 선형 회귀를 이용하여 문제를 풀어보자. 어떤 학생의 공부 시간에 따라 다음과 같은 점수를 얻었다고 가정하고, 좌표 평면에 그려보자.
알고있는 데이터로부터 x와 y의 관계를 유추하고, 이 학생이 6시간, 7시간, 8시간을 공부하였을 때의 성적을 예측해보고 싶다. x와 y의 관계를 유추하기 위해서 수학적으로 식을 세워보게 되는데 머신 러닝에서는 이러한 식을 가설(Hypothesis)이라고 한다. 사실 선형 회귀의 가설은 이미 아래와 같이 널리 알려져있다.
위 그림은 W와 b의 값에 따라서 천차만별로 그려지는 직선의 모습을 보여준다. W는 직선의 기울기고, b는 절편으로 직선을 표현함을 알 수 있다. 결국 선형 회귀는 주어진 데이터로부터 y와 x의 관계를 가장 잘 나타내는 직선을 그리는 일을 말한다.
그러면 어떻게 가장 최적의 직선을 그릴 수 있을까?
1.3 비용 함수(Cost function) : 평균 제곱 오차(MSE)
머신 러닝은 W와 b를 찾기 위해서 실제값과 가설로부터 얻은 예측값의 오차를 계산하는 식을 세우고, 이 식의 값을 최소화하는 최적의 W와 b를 찾아낸다. 이 때 실제값과 예측값에 대한 오차에 대한 식을 목적 함수(Objective function) 또는 비용 함수(Cost function) 또는 손실 함수(Loss function)라고 한다.
비용 함수는 단순히 실제값과 예측값에 대한 오차를 표현하면 되는 것이 아니라, 예측값의 오차를 줄이는 일에 최적화 된 식이어야 한다. 즉, 다양한 문제들에 적합한 비용 함수들이 있다는 것이다. 회귀 문제의 경우에는 주로 평균 제곱 오차(Mean Squared Error, MSE)가 사용된다.
위 그래프에서 그린 직선은 임의로 그린 직선으로 정답이 아니다. 이제 이 직선을 서서히 W와 b의 값을 바꾸면서 정답인 직선을 찾아내야 한다. y와 x의 관계를 가장 잘 나타내는 직선을 그린다는 것은 위의 그림에서 모든 점들과 위치적으로 가장 가까운 직선을 그린다는 것과 같다.
자 그럼 오차를 구해보자. 오차는 주어진 데이터에서 각 x에서의 실제 값 y와 위의 직선에서 예측하고 있는 H(x) 값의 차이를 말한다. 즉 위의 그림에서 빨간 화살표가 각 점에서 오차의 크기를 보여준다. 즉, 이 오차를 줄여가면서 W와 b의 값을 찾아내기 위해 전체 오차의 크기를 구해야 한다.
오차의 크기를 측정하기 위한 가장 기본적인 방법은 각 오차를 모두 더하는 방법이다. 그런데 수식적으로 단순히 '오차 = 실제값 - 예측값'이라 정의한 후에 모든 오차를 더하면 음수 오차도 있고, 양수 오차도 있으므로, 오차의 절대적인 크기를 구할 수가 없다. 그래서 모든 오차를 제곱하여 더하는 방법을 사용한다. 여기서 데이터 개수 만큼 나누어 평균을 구한다. 그리하여 평균 제곱 오차를 구할 수 있다. 수식으로 보면 다음과 같다. $cost(W,b)=\frac{1}{n}\sum^{n}_{i=1}[y^{(i)}-H(x^{(i)})]^2$
모든 점들과의 오차가 클 수록 이 값은 커지고, 오차가 작을 수록 평균 제곱 오차는 작아진다. 결과적으로 이 Cost(W,b)가 최소가 되게 만드는 W와 b를 구하면 y와 x의 관계를 가장 잘 나타내는 직선을 그릴 수 있다.
1.4 옵티마이저(Optimizer) : 경사하강법(Gradient Descent)
선형 회귀를 포함한 수많은 머신 러닝, 딥 러닝의 학습은 결국 비용 함수를 최소화하는 매개 변수인 W와 b를 찾기 위한 작업을 수행한다. 이때 사용되는 알고리즘을 옵티마이저(Optimizer) 또는 최적화 알고리즘이라고 부른다.
이 옵티마이저를 통해 적절한 W와 b를 찾아내는 과정을 머신 러닝에서 학습(traning)이라고 부른다. 가장 기본적인 옵티마이저 알고리즘인 경사 하강법(Gradient Descent)에 대해 알아보자. 그전에 cost와 기울기 W와의 관계를 살펴보면, 아래 그래프를 통해 W가 지나치게 높거나 낮을 때 어떻게 오차가 커지는지 보여준다.
주황색 선은 기울기 W가 20일 때, 초록색 선은 1일 때를 보여준다. 설명의 편의를 위해 편향 b가 없이 단순히 가중치 W만을 사용한 가설을 가지고 경사 하강법을 수행한다고 해보자. 이런 기울기 W와 cost 함수와의 관계를 그래프로 표현하면 아래와 같다.
기울기 W가 무한대로 커지거나 작아진다면 cost 값 또한 무한대로 커진다. 위 그래프에서 cost가 가장 작을 때는 볼록한 부분의 맨 아래 부분이다. 기계는 이 cost가 가장 최소값을 가지게 하는 W를 찾는 일이다.
기계는 임의의 랜덤 W값을 정한 뒤, 맨 아래 볼록한 부분을 향해 점차 W의 값을 수정해 나간다. 이를 가능하게 하는 것이 경사 하강법(Gradient Descent)이며, 수행하기 위해서는 미분을 이해해야 한다. 미분의 개념 중 한 점에서의 순간 변화율 또는 접선에서의 기울기의 개념을 이용한다.
위 그림에서 초록색 선은 W가 임의의 값을 가지게 되는 네 가지의 경우에 대해서, 그래프 상으로 접선의 기울기를 보여준다. 주목할 것은 맨 아래의 볼록한 부분으로 갈수록 접선의 기울기가 점차 작아진다는 점이다. 그렇게 점차 작아지다가 cost가 최소가 되는 지점에서 접선의 기울기가 0이 된다. 즉, 경사하강법의 아이디어는 비용 함수(cost function)를 미분하여 현재 W에서 접선의 기울기를 구하고, 접선의 기울기가 낮은 방향으로 W의 값을 변경하고 이 과정을 접선의 기울기가 0인 곳을 향해 W의 값을 변경하는 작업을 반복하는 것에 있다.
위의 식은 현재 W에서의 접선의 기울기와 $\alpha$를 곱한 값을 현재 W에서 빼서 새로운 W의 값으로 정한다는 것(update)을 의미한다. 여기서 $\alpha$는 학습률(learning rate)이라고 하는데, 우선은 현재 W에서 현재 W의 접선의 기울기를 뺴는 행위가 어떤 의미인지 보자.
위 그림에서 접선의 기울기가 음수일 때, 0일 때, 양수일 때의 경우를 보여준다. 위에서 W 값을 update하는 식을 사용하면 식이 아래와 같이 변형 될 수 있다.
$W := W - \alpha \times (-기울기) = W + \alpha \times (기울기)$
W의 값이 더해지면서 0에 가까운 방향으로 수정됨을 알 수 있다. 반대의 경우는 어떨까? 기울기가 양수일 경우면 다음과 같이 된다.
$W := W - \alpha \times (기울기)$
양수일 때에는 W값이 매우 컷기 때문에 빼준다. 결과적으로 기울기가 0인 방향으로 W값이 조정된다. 그렇다면 여기서 학습률(learning rate)는 무슨 의미일까? 학습률 $\alpha$는 W의 값을 변경할 때, 얼마나 크게 변경할지를 결정한다. 또는 W를 그래프의 한 점으로보고 접선의 기울기가 0일 때까지 경사를 따라 내려간다는 관점에서는 얼마나 큰 폭으로 이동할지를 결정한다.
직관적으로 생각하기에 학습률 $\alpha$의 값을 무작정 크게 하면 금방 기울기가 0이 되는 W를 찾을 수 있을 것 같지만 그렇지 않다.
위 그림은 학습률 $\alpha$가 지나치게 높은 값을 가질 때, 접선의 기울기가 0이 되는 W를 찾아가는 것이 아니라 W의 값이 발산하는 상황을 보여준다. 반대로 학습률이 지나치게 낮은 값을 가지면 학습 속도가 느려지므로 적당한 $\alpha$값을 찾아내는 것도 중요하다.
2. 로지스틱 회귀(Logistic Regression)
일상 속 풀고자하는 많은 문제 중 두 개의 선택지 중에서 정답을 고르는 문제가 많다. 이렇게 둘 중 하나를 결정하는 문제를 이진 분류(Binary Classification)라고 한다. 그리고 이런 문제를 풀기 위한 대표적인 알고리즘으로 로지스틱 회귀(Logistic Regression)가 있다.
2.1 이진 분류(Binary Classification)
앞서 설명한 선형 회귀 챕터에서 공부 시간과 성적 간의 관계를 직성의 방정식으로 표현을 했다. 하지만 이번 문제는 직선으로 표현하는 것이 적절하지 않다.
학생들이 시험 성적에 따라 합격, 불합격이 기재된 데이터가 있다고 가정해보자. 시험 성적이 x라면 합불 결과는 y다. 이 시험의 커트라인은 공개되지 않았는데 이 데이터로부터 특정 점수를 얻었을 때의 합격, 불합격 여부를 판정하는 모델을 만든다고 하자.
이러한 점들을 표현하는 그래프는 알파벳의 S자 형태로 표현된다. 이런 x,y 관계를 표현하기 위해서는 S자 형태로 표현할 수 있는 함수가 필요하다. 또한 실제값 y가 0또는 1이라는 두 가지 값밖에 가지지 않으므로 이 문제를 풀기 위해서 예측값이 0과 1사이의 값을 가지도록 하는 것이 보편적이다. 이 값을 확률로 해석하면 문제를 풀기가 훨씬 용이해진다. 최종 예측값이 0.5보다 작으면 0으로 예측했다고 판단하고, 0.5보다 크면 1로 예측했다고 판단할 수 있기 때문이다.
이 조건들을 충족하는 함수가 있다. 그것은 바로.. 시그모이드 함수(Sigmoid function)이다.
2.2 시그모이드 함수(Sigmoid function)
시그모이드 함수의 방정식부터 살펴보자. 종종 $\sigma$로 축약해서 표현하기도 한다. 이는 위 문제를 풀기 위한 가설식이기도 한다. $H(X) = \frac{1}{1+e^{-(Wx+b)}} = sigmoid(Wx+b) = \sigma(Wx+b)$
여기서 e는 자연 상수다. 여기서 구해야할 것은 여전히 주어진 데이터에 가장 적합한 가중치 W(Weight)와 편향 b(Bias)이다. matplotlib을 이용하여 시그모이드 함수 그래프를 쉽게 그려볼 수 있다.
%matplotlib inline
import numpy as np # 넘파이 사용
import matplotlib.pyplot as plt # 맷플롯립 사용
def sigmoid(x):
return 1/(1+np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y, 'g')
plt.plot([0,0],[1.0,0.0], ':') # 가운데 점선 추가
plt.title('Sigmoid Function')
plt.show()
위의 그래프는 가중치(W)는 1, 편향(b)은 0임을 가정한 그래프입니다.
여기서 구해야할 가중치 W와 편향 b가 어떤 의미를 가지는지 한 번 그래프를 통해 알아보자.
def sigmoid(x):
return 1/(1+np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y1 = sigmoid(0.5*x)
y2 = sigmoid(x)
y3 = sigmoid(2*x)
plt.plot(x, y1, 'r', linestyle='--') # W의 값이 0.5일때
plt.plot(x, y2, 'g') # W의 값이 1일때
plt.plot(x, y3, 'b', linestyle='--') # W의 값이 2일때
plt.plot([0,0],[1.0,0.0], ':') # 가운데 점선 추가
plt.title('Sigmoid Function')
plt.show()
위 그래프는 W의 값이 0.5일때 빨간색선, 1일때 초록색선, 2일때 파란색선이 나오도록 했다. 그 결과 W 값의 변화를 통해 경사도가 변하는 것을 알 수 있다. 즉 W의 값이 커지면 경사가 커지고, 작아지면 완만해짐을 알 수 있다.
b 값의 변화에도 그래프가 어떻게 변하는지 확인해보자.
def sigmoid(x):
return 1/(1+np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y1 = sigmoid(x+0.5)
y2 = sigmoid(x+1)
y3 = sigmoid(x+1.5)
plt.plot(x, y1, 'r', linestyle='--') # x + 0.5
plt.plot(x, y2, 'g') # x + 1
plt.plot(x, y3, 'b', linestyle='--') # x + 1.5
plt.plot([0,0],[1.0,0.0], ':') # 가운데 점선 추가
plt.title('Sigmoid Function')
plt.show()
b의 값이 0.5 일때 빨간색, 1일 때 초록색, 1.5일때 파란색이다. 중심을 기준으로 봤을 때 좌우로 움직이는 것을 볼 수 있다. 즉 W와 b를 변경하면서 최적의 x와 y의 값을 표현하는 S자 그래프를 찾아가는 것이다. 시그모이드 함수는 입력값이 커지면 1에 수렴하고, 입력값이 작아지면 0에 수렴한다. 그리고 0부터 1까지의 값을 가지므로 출력값이 0.5 이상이면 1(True), 0.5이하면 0(False)로 만들면 이진 분류 문제로 사용할 수 있다. 이를 확률이라고 생각하면 해당 범주에 속할 확률이 50%가 넘으면, 해당 범주라고 판단하고 낮으면, 아니라고 판단한다고도 볼 수 있다.
2.3 비용 함수(Cost Function)
로지스틱 회귀 또한 경사 하강법을 사용하여 가중치 W를 찾아내지만, 비용 함수로는 평균 제곱 오차를 사용하지 않는다. 시그모이드 함수에 비용함수를 평균 제곱 오차로 하여 그래프를 그리면 다음과 비슷한 형태가 되기 때문이다.
로지스틱 회귀에서 평균 제곱 오차를 비용 함수로 사용하면, 경사 하강법을 사용할 때 자칫 잘못하면 찾고자 하는 최소값이 아닌 잘못된 최소값에 빠진다. 이를 전체 함수에 걸쳐 최소값인 글로벌 미니멈(Global minimum)이 아닌 특정 구역에서의 최소값인 로컬 미니멈(Local minimum)에 도달했다고 한다. 이는 cost가 최소가 되는 가중치 W를 찾는다는 비용 함수의 목적에 맞지 않다.
우리의 목표는 위의 미완성 식을 가중치를 최소화하는 적절한 목적 함수를 만드는 것이다. 여기서 J는 목적 함수(objective function)이고, H(x)는 예측값, y는 실제값이다. 시그모이드 함수는 0과 1사이의 y값을 반환한다. 이는 실제값이 0일 때 예측값이 반대인 1에 가까워 질 때 오차가 커짐을 할 수 있다. 이를 반영할 수 있는 함수는 로그 함수를 통해 표현이 가능하다.
👆 log x는 x의 값이 0에 가까울 수록 음의 무한대 값으로 발산하고, 1에 가까울 수록 0에 수렴한다.
$if y = 1 -> cost(H(x),y) = - log(H(x))$ $if y = 0 -> cost(H(x),y) = - log(1-H(x))$
즉 실제값이 1일 때의 예측값인 H(X)의 값이 1이면 오차가 0이므로 당연히 cost는 0이 된다. 반면, H(X)가 0으로 수렴하면 cost는 무한대로 발산한다. 이는 다음과 같이 하나의 식으로 표현할 수 있다.
$cost(H(x),y) = -[ylogH(x) + (1-y)log(1-H(x))]$
자세히 보면 y와 (1-y)가 식 중간에 들어갔고, 두 개의 식을 -로 묶은 것 외에는 기존의 두 식이 들어가 있는 것을 볼 수 있다.
이때 로지스틱 회귀에서 찾아낸 비용함수를 크로스 엔트로피(Cross Entropy)함수라고 한다. 즉, 결론적으로 로지스틱 회귀는 비용 함수로 크로스 엔트로피 함수를 사용하며, 가중치를 찾기 위해서 크로스 엔트로피 함수의 평균을 취한 함수를 사용한다. 크로스 엔트로피 함수는 소프트맥스 회귀의 비용 함수이기도 하다.
➕ cross entropy에 대해..
우선 entropy는 정보량을 의미한다. 불확실성(랜덤성)이 클수록 entropy 값이 커진다고 한다. (+모든 사건이 같은 확률로 일어나는 것이 가장 불확실하다고 한다.)
그럼 cross entropy는 두 가지의 경우에 entropy를 비교하는 것이 아닐까 라는 추측을 조심스래 해본다. 수식으로 먼저 보자. $H(p,q) = \sum_{i} p_i log_2\frac{1}{q_i} = -\sum_{i} p_i log_2 q_i$ 대개 머신러닝에서 cross entropy를 사용할 때, $p_i$ 가 특정 확률에 대한 참값 또는 목표 확률이고, $q_i$가 우리가 예측한 확률 값이 된다. 즉, $q_i$를 학습하고 있는 상태라면 $p_i$에 가까워질수록 cross entropy의 값은 작아지게 된다.
cross entropy는 log loss로 불리기도 한다. cross entropy를 최소화하는 것은 log likeihood를 최대화하는 것과 같기 때문이다. ->아직 이 말이 왜 그런지 이해하진 못했다. 어떤 데이터가 0 또는 1로 predict될 확률은 $\hat{y}, 1-\hat{y}$ 이므로 y가 0과 1의 값만 가질 때 likelihood식을 이렇게 세울 수 있다고 한다. $\hat{y}^y(1-\hat{y})^{(1-y)}$
y=1일 때 $\hat{y}$ 최대화 시켜야하고, y=0일 때는 $(1-\hat{y})$를 최대화시켜야 한다. 여기에 log를 씌우면 다음과 같이 정리 된다. $maximize : y log \hat{y} + (1-y)log(1-\hat{y}) = minimize : -y log \hat{y} + (1-y)log(1-\hat{y})$ 최소화 해야 하는 식은 우리가 방금 살펴본 cross entropy와 똑같은 식이다. 이러한 이유로 log loss라고 부르기도 한다. 또 나아가 자연스럽게 cross entropy는 negative log likelihood로 불리기도 한다.
요약
binary classification에 나오는 logistic regression cost function은 cross entropy 식과 같다.
cross entropy와 log loss, negative log likelihood 다 유사하게 쓰이는 것 같다.
결국 훈련시 cross entropy로 두 확률 분포간의 차이를 loss 값으로 이용하여 파라미터를 수정하는 것 같다.
위 내용은 현재까지 내가 이해한 것이며, 답이 아님을 말하고 싶다. 아직 정확히 내가 이해하지 못하고 적은 것이라 제대로 알게 될 때마다 수정하려고 한다. 잘못된 것이 있다면 참고링크나, 알려주시면 감사하겠습니다~~
AI는 여러 의미를 포괄하고 있지만, 지금에 이르러 사람들이 말하는 AI는 바로 머신 러닝(Machine Learning)과 머신 러닝의 한 갈래인 딥 러닝(Deep Learning)을 의미한다. 스스로 규칙을 찾아내가는 머신 러닝이 새로운 프로그래밍의 패러다임이 될 것이라 말하기도 한다. 그럼 머신러닝이란 도대체 무엇인가... 시작해보자!
1. 머신러닝이란(Machine Learning)?
왜 이것이 나오게 되었는가 부터 찬찬히 살펴보자.
1.1 머신러닝이 아닌 접근 법의 한계
예를들어 '주어진 사진으로부터 고양이 사진인지 강아지 사진인지 판별하는 일' 이라는 해결 해야 할 문제가 주어졌다고 가정하자.
이 문제를 사람이라면 구분을 잘 하겠지만, 컴퓨터가 이것을 구분하게 한다는 것은 쉽지가 않다. 전통적인 방식으로 개발자가 직접 규칙을 정의하여 프로그램을 작성한다면 다음과 같을 것이다.
def prediction(이미지파일):
if 눈코귀가 있을 때:
if 근데 강아지는 아닐때
if 털이 있고 꼬리 있을 때:
if 다른 동물이 아닐 때
...
어캐하누...
return 결과
위의 사진에서 볼 수 있는 것처럼, 고양이 자세나 색상 등이 너무 다양해서 공통된 명확한 특징을 모두 잡아내는 것은 사실상 불가능에 가깝다고 볼 수 있다. 존재하지도 않지만, 있다해도 어떻게 저런 것을 사람이 다 일일이 정의를 하나...
그래서 이미지 인식 분야에서 특징을 잡아내기 위한 시도들이 있었다. 이미지의 shape이나 edge와 같은 것들을 찾아내서 알고리즘화 하려고 시도하고, 다른 사진 이미지가 들어오면 전반적인 상태를 비교하여 분류하려고 한 것이다. 그렇지만 여전히 공통된 명확한 특징을 찾아내는 것에 한계가 있을 수 밖에 없기에, 머신러닝이 이에 대한 해결책이 될 수 있다.
1.2 정리
간단하게 설명하자면,
기존의 프로그래밍이 개발자가 직접 규칙을 정의하여 input(data)을 넣어서 output(해답)을 도출했다.
Ex) input(사진) ---> fucntion(정의한 규칙 : 꼬리와 털이 있으면 고양이다.) ---> output(고양이다)
하지만 머신러닝은 개발한 알고리즘을 통해 만든 model에 input(data와 해답)을 넣어 규칙을 도출해낸다.
Ex) input(사진, 고양이다) ---> model(학습) ---> output(학습한 규칙 : 꼬리와 털이 있으면 고양이다.)
이렇게 학습한 모델은 기존 프로그래밍처럼 input으로 data가 들어온다면 해답을 예측(추론)할 수 있게 된다.
결과적으로 머신러닝은 주어진 데이터로부터 결과를 찾는 것에 초점을 맞추는 것이 아니라, 주어진 데이터로부터 규칙성을 찾는 것에 초점이 맞추어져 있다. 주어진 데이터로부터 규칙성을 찾는 과정을 학습(training)이라고 한다.
대충 느낌은 왔으니 조금만 더 들어가 보자!
2. 머신러닝 훑어보기
머신 러닝의 특징들에 알아보자. 딥 러닝 또한 머신 러닝에 속하므로 머신러닝의 특징들은 모두 딥러닝의 특징이기도 하다.
2.1 머신 러닝 모델의 평가
모델을 학습시켰다면, 평가를 빼놓을 수가 없다. 모델을 학습시켰는데 이것이 잘된건지 아닌지 확인을 해야 사용할 수 있을지 아닐지 판단할 수 있지 않겠는가? 그래서 실제 모델을 평가하기 위해 데이터를 훈련용, 검증용, 테스트용 이렇게 세 가지로 분리하는 것이 일반적이다.
근데 훈련이랑 테스트로 한 번만 테스트하면 되지, 굳이 검증까지 넣어뒀을까 싶다. 역시 사람들이 만들어둔 것은 다 이유가 있다. 검증용 데이터는 모델의 성능을 평가하기 위한 용도가 아니라, 모델의 성능을 조정하기 위한 용도이다. 더 자세히는 과적합이 되고 있는지 판단하거나 하이퍼파라미터의 조정을 위한 용도이다.
👆 여기서 하이퍼파라미터(hyper parameter)란?
값에 따라서 모델의 성능에 영향을 주는 매개변수를 말한다.
경사하강법에서 학습률(learning rate), 딥러닝에서 은닉층의 수, 뉴런의 수, 드롭아웃 비율 등이 이에 해당한다.
반면, 일반 매개변수(일반 파라미터)는 가중치와 편향과 같은 학습을 통해 바뀌어져가는 변수이다.
정리하면, 하이퍼파라미터 = 사람이 정하는 변수 / 파라미터(매개변수) = 기계가 훈련을 통해 바꾸는 변수
아무튼! 훈련용 데이터로 훈련을 모두 시킨 모델은 검증용 데이터를 사용하여 정확도를 검증하며 하이퍼파라미터를 튜닝(tuning)한다. 그러면 이 모델의 매개변수는 검증용 데이터에 대해 일정 부분 최적화가 된다. 튜닝하면서 다시 훈련을 검증용 데이터를 사용했기에 검증을 아직까지 보지 못한 데이터로 하는 것이 바람직하다. 그래서 이제 테스트 데이터로 모델의 진짜 성능을 평가한다.
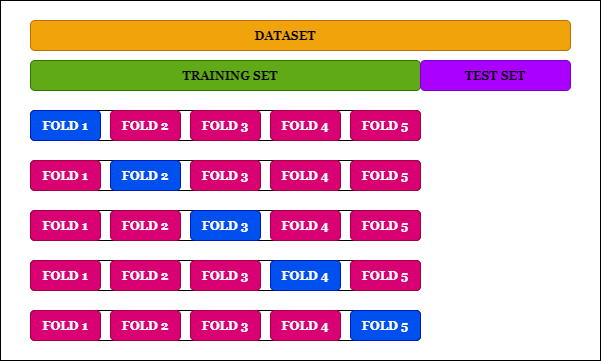
결과적으로 훈련 과정을 수험생으로 비유를 하자면 훈련데이터(문제집) -> 검증데이터(모의고사) -> 테스트데이터(수능) 이라고 볼 수 있다. 문제집을 쭉 풀다가 모의고사를 보고 아 유형이 이런식이구나 하면서 모의고사에 맞춰서 공부하는 것이다. 그런 다음 마지막으로 수능을 치는 것과 같이 평가를 하는 것이다. 데이터가 충분하지 않으면 이렇게 3개로 나누는 것이 힘들 것이다. 그럴 때 k-폴드 교차 검증이라는 또 다른 방법을 사용하기도 한다.
간단하게 말하자면, 테스트 세트를 제외한 데이터셋을 K개로 분할하여 나눈뒤, 검증용 데이터 부분을 바꿔가면서 각 case별로 정확도를 측정해보는 것이다. 자세히 알고싶다면 이곳을 살펴보자.
2.2 분류(Classification)와 회귀(regression)
다음으로는 머신러닝이 어떤 문제를 해결하는데 사용되는지 알아보자. 전부라고는 할 수 없지만, 머신 러닝의 많은 문제는 분류 또는 회귀 문제에 속한다.
1️⃣ 이진 분류 문제(Binary Classification)
이진 분류는 주어진 입력에 대해서 둘 중 하나의 답을 정하는 문제이다.
시험 성적에 대해 합격/불합격 또는 메일로부터 정상메일인지 스팸메일인지를 판단하는 문제 등이 이에 속한다.
2️⃣ 다중 클래스 분류(Multi-Class Classification)
주어진 입력에 대해 두개 이상의 정해진 선택지 중에서 답을 정하는 문제이다.
서점을 예로 들면 책 분야를 과학, 영어, IT, 만화 라는 레이블이 각각 붙어있는 4개의 책장이라 하면, 새 책이 입고 되면 이 책을 분야에 맞는 적절한 책장에 넣어야 한다. 이 때의 4개의 선택지를 카테고리 또는 범주 또는 클래스라고 한다. 결과적으로 주어진 입력으로부터 정해진 클래스 중 하나로 판단하는 것이다.
3️⃣ 회귀 문제(Regression)
회귀 문제는 분류 문제처럼 0 또는 1이나 다양한 분야가 있는 책 분류와 같이 분리된(비연속적인) 답이 결과가 아니라 연속된 값을 결과로 가진다.
대표적으로 시계열 데이터를 이용한 주가 예측, 생산량 예측, 지수 예측 등이 이에 속한다.
2.3 지도 학습(Supervised Learning)과 비지도 학습(Unsupervised Learning)
그러면 어떤 방법으로 학습하는지도 알아야지 않겠는가. 머신러닝은 크게 지도 학습, 비지도 학습, 강화 학습으로 나눈다. 강화 학습은 이 책에서 다루지 않으므로 두 가지만 알아보도록 하겠다.
1️⃣ 지도 학습
지도학습이란 레이블(Label)이라는 정답과 함께 학습하는 것을 말한다. 레이블이라는 말 외에도 y, 실제값 등으로 부르기도 한다.
기계는 예측값과 실제값인 차이인 오차를 줄이는 방식으로 학습을 하게 된다. 예측값은 $\hat{y}$으로 표기하기도 한다.
2️⃣ 비지도 학습
레이블이 없이 학습을 하는 것을 말한다. 예를들어 토픽 모델링의 LDA는 비지도 학습에 속하고 word2vec도 비지도 학습에 속한다.
2.4 샘플(Sample)과 특성(Feature)
중요 용어에 대해 알아보자. 많은 머신 러닝 문제가 1개 이상의 독립 변수 x를 가지고 종속 변수 y를 예측하는 문제이다. 많은 머신 러닝 모델들, 특히 인공 신경망 모델은 독립 변수, 종속 변수, 가중치, 편향 등을 행렬 연산을 통해 연산하는 경우가 많다. 그래서 행렬을 자주 보게 될 것인데, 독립 변수 x의 행렬을 X라고 했을 때, 독립 변수의 개수가 n개 이고 데이터의 개수가 m인 행렬 X는 다음과 같다.
이때 머신 러닝에서는 하나의 데이터, 하나의 행을 샘플(Sample)이라 부르고, 종속 변수 y를 예측하기 위한 각각의 독립 변수x를 특성(Feature)이라고 부른다.
2.5 혼동 행렬(Confusion Matrix)
머신 러닝에서는 맞춘 문제수를 전체 문제수로 나눈 값을 정확도(Accuracy)라고 한다. 하지만 정확도는 맞춘 결과와 틀린 결과에 대한 세부적인 내용을 알려주지는 않는다. 이를 위해 사용하는 것이 혼동 행렬이다.
예를 들어 양성(Positive)과 음성(Negative)을 구분하는 이진 분류가 있다고 했을 때 혼동 행렬은 다음과 같다.
True 는 정답을 맞춘 경우고, False는 정답을 맞추지 못한 경우다. 그리고 positive와 Negative는 예측된 값들이다. 이를 통해 다음과 같이 알 수 있다. FP는 양성이라 예측했는데, 실제론 음성인 경우이고, FN은 음성이라 예측했는데 실제론 양성인 경우이다.
이 개념을 사용하면 또 새로운 개념인 정밀도(Precision)과 재현율(Recall)이 된다.
1️⃣ 정밀도(Precision)
정밀도는 양성이라고 대답한 전체 케이스에 대한 TP(예측과 정답이 양성으로 같은 경우) 비율이다. 즉, 정밀도를 수식으로 표현하면 다음과 같다.
$ 정밀도 = \frac{TP}{TP + FP} $
2️⃣ 재현율(Recall)
재현율은 실제 값이 양성인 데이터의 전체 개수에 대해서 TP(예측과 정답이 양성으로 같은 경우)의 비율이다. 즉, 양성인 데이터 중에서 얼마나 양성인지를 예측(재현)했는지를 나타낸다.
$ 재현율 = \frac{TP}{TP + FN} $
🤔 근데 이것들을 왜 구해서 어디다 쓰는 것인가?
정의되는 문제의 종류에 따라 다르다.
재현율은 실제값이 positive일 때 예측한 값이 positive일 경우가 중요한 상황일 때 사용된다. 즉 잘못 예측해도 negative인 경우가 적은게 나을 때이다. 단적인 예로, 암 판단 분류 예측을 하는 문제에 있어서 실제로 암이 걸렸는데 예측을 암이 걸리지 않았다고 판단하게 되면 수반되는 위험이 매우 커지기 때문이다.
반대로 정밀도는 모델이 예측한 것이 틀려도 Posivite인 경우가 적은게 나을 경우에 사용된다. 예시로 스팸메일 분류를 생각해보자. 만약 분류 모델이 중요한 업무내용을 담고 있는 메일(Negative)을 스팸메일(Positive)이라 분류하게 된다면 전달되지 못하는 위험한 상황이 발생한다.
➕ F1-score
추가로 성능측정 지표로 F1-score 라는 것이 있는데, 이것은 정밀도와 재현율의 조화평균이다. 수식은 다음과 같다.
$F1Score = 2 * \frac{(재현율 * 정밀도)}{(재현율 + 정밀도)}$
주로 다중 클래스를 분류 모델의 성능 측정 지표로 많이 사용되는데, 이 이유는 단순 정확도(Accuracy)를 구할 때에 데이터가 특정 클래스로 쏠려있는 경우일 때 정확도가 높은 수치를 나타내지만 실제론 그렇지 않은 경우가 생기기 때문이다.
출처 : https://nittaku.tistory.com/295
위 사진과 같이 수치는 model2가 훨씬 정확하다고 하지만, model2는 B,C,D에서 10개중 1개 밖에 못맞추는 모델이다. 즉, A만 잘맞추는 모델이 된 것이다. 그렇기에 model2가 model1 보다 좋다고 얘기할 순 없는 것이다.
이렇게 데이터가 균등하지 못한 경우 성능측정을 f1-score를 사용한다. 즉, 조화평균은 단순하게 평균을 구하는 것이 아니라, 큰 값이 있다면 패널티를 주어서, 작은값 위주로 평균을 구하게 된다.
2.6 과적합(Overfitting)과 과소 적합(Underfitting)
학생의 입장이 되어 같은 문제지를 과하게 많이 풀어 문제 번호만 봐도 정답을 맞출 수 있게 되었다 가정하자. 그런데 다른 문제지나 시험을 보면 점수가 안 좋다면 그게 의미가 있을까?
머신러닝에서 이러한 경우와 같이 훈련 데이터를 과하게 학습한 경우를 과적합(Overfitting)이라고 한다. 즉 훈련 데이터에 대해 지나친 일반화를 한 상황이다. 그 결과 훈련 데이터에 대해서 오차가 낮지만, 테스트 데이터에 대해서는 오차가 높아지는 상황이 발생한다. 아래의 스팸 필터 분류기를 예제를 살펴보자.
훈련 횟수가 3~4회를 넘어가게 되면 오차(loss)가 점차 증가하는 양상을 보여준다. 훈련데이터에 대해서는 정확도가 높지만, 테스트 데이터는 정확도가 점차 낮아진다고 볼 수 있다.
그래서 과적합을 방지하기 위해 테스트 데이터에 대한 loss값이 크게 높아지기 전에 훈련을 멈추는 것이 바람직 하지만, 반대로 테스트 데이터의 성능이 올라갈 여지가 있음에도 훈련을 덜 한 상태가 있을 수 있다. 이러한 경우를 과소적합(Underfitting)이라 한다. 훈련자체가 부족한 상태이므로 훈련데이터에 대해서도 보통 정확도가 낮다는 특징이 있다.
딥 러닝을 할 때는 과적합을 막을 수 있는 드롭 아웃(Drop out), 조기 종료(Early Stopping)과 같은 몇 가지 방법이 존재한다. 그 전까지 차근차근 공부해 나가자~!