👋 개요
한글 자연어처리 라이브러리로 konlpy나 mecab을 사용하여 형태소 분석이나, 명사추출을 할 때, 신조어나 복합명사들이 제대로 추출되지 않는 경우가 있다. 그런 경우 따로 분석기에 사용자 사전을 추가해서 그러한 문제를 보완할 수 있다.
하지만 매번 사람이 일일이 다 찾아서 작성할 순 없는 노릇이다. 그러면 어떻게 하면 좋을까? 🤔
👍 soynlp
한국어 분석을 위한 한국어 자연어처리 라이브러리다. 학습데이터를 이용하지 않으면서 데이터에 존재하는 단어를 찾거나, 문장을 단어열로 분해, 혹은 1품사 판별을 할 수 있는 비지도학습 접근법을 지향한다. 여러가지 버전의 명사 추출기를 제공하고 있다.
from soynlp.noun import NewsNounExtractor
noun_extractor_news = NewsNounExtractor(
max_left_length=10,
max_right_length=7,
predictor_fnames=None,
verbose=True
)
nouns_news = noun_extractor_news.train_extract(sentences)
# 출력
used default noun predictor; Sejong corpus based logistic predictor
/Users/dong/opt/anaconda3/envs/cow_word/lib/python3.7/site-packages/soynlp
local variable 'f' referenced before assignment
local variable 'f' referenced before assignment
scan vocabulary ...
done (Lset, Rset, Eojeol) = (518797, 290268, 289869)
predicting noun score was done
before postprocessing 138637
_noun_scores_ 30616
checking hardrules ... done0 / 30616+(이)), NVsubE (사기(당)+했다) ... done
after postprocessing 21026
extracted 985 compounds from eojeolss ... 45000 / 45737
그 중에서 나는 많은 기능을 포함하고 있는 NewsNounExtractor 를 사용했다. 왜냐하면 뉴스 데이터를 사용하기도 하고, 여러가지 속성들을 가지고 있기 때문이다.
아직 감이 안오니 어서 출력해보자. score를 기준으로 내림차순 정렬을 해서 200개만 출력해봤다.
sort_nouns_news = sorted(nouns_news.items(), key=lambda x:-x[1].score)[:200]
print(tmp_)
# 출력
[('기초수급자',
NewsNounScore(score=1.0, frequency=16, feature_proportion=0.25, eojeol_proportion=0.5, n_positive_feature=1, unique_positive_feature_proportion=1.0)),
...]
출력결과를 보면 7개 가량의 속성이 있음을 알 수 있다. 그 중에서 나는 score, frequency, feature_proportion 이 세 가지에 집중해봤다.
1️⃣ score : 명사 가능성을 점수로 표현했으며, 튜토리얼 문서에 따르면 한국어는 L + [R] 구조이며, 명사 뒤에 나오는 R set을 모아 명사 가능 점수를 학습 시켜놨다. R set에 '있게'는 1.0점, '있는'은 0.3 점이라 등록되었다 가정하고, '재미 + 있게' 3번, '재미 + 있는' 2번 등장하였다면 재미의 명사 가능 점수는 (3 x 1.0 + 2 x 0.33) / 5 = 0.732점 이라고 한다.
2️⃣ frequency : 딱 보면 느낌오겠지만, 그 단어가 나온 빈도수이다.
3️⃣ feature_proportion : 이것에 대해 제대로 나오진 않았지만, 번역기 돌려보면 특성이 있는지(?) 정도로 추측이 된다.
🤩 아이디어
soynlp를 활용하여 미등록단어 문제를 해결할 수 있지 않을까? 라는 생각을 해보았다.
그래서 떠오른 아이디어는 뉴스데이터를 크롤링하여 soynlp의 명사추출기로 추출된 명사를 10개씩 ' '(공백)으로 이어 붙여 형태소 분석기(사용한 것은 mecab)을 통해 명사 분석한다. mecab을 통해 나온 output을 input으로 넣었던 명사와 비교하여 분석되지 않은 명사가 어떤 것인지 살펴보는 것이다!
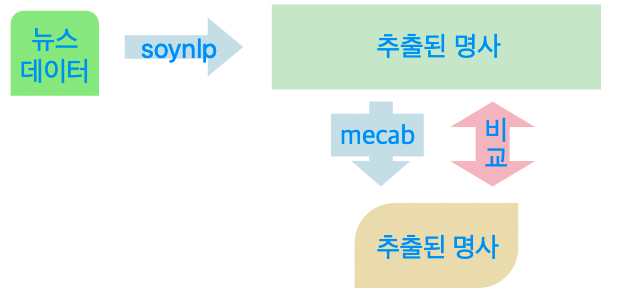
글로 적으니까 햇갈리니 허접하지만 직관적인 플로우 차트를 그려봤다.
아무튼 느낌은 왔으니 실제로 해봐야 알 것 아닌가??
🤔 진행과정
데이터는 우선 네이버 뉴스데이터에서 크롤링을 했고, soynlp로 추출된 명사는 score * frequency * feature_proportion 계산을 하여 높은 순서대로 상위 200개를 사용했다.(➕ 글자수가 2개 이하인 것들은 제외했다.)
nouns_news_tmp = {key: value for key, value in nouns_news.items() if len(key) > 2}
top_news = sorted(nouns_news_tmp.items(),
key=lambda x:-x[1].frequency * x[1].score * x[1].feature_proportion)[:200]
for i, (word, score) in enumerate(top_news):
if i % 4 == 0:
print()
print('%6s (%.2f)' % (word, score.score), end='')
# 출력
오마이뉴스 (0.99) 이재명 (0.96) 코로나19 (0.95) 페이스북 (0.89)
상대적 (1.00) 시민들 (0.82)최고위원회의 (0.97) 간담회 (0.88)
김현정 (1.00) 그동안 (0.82) 세금으로 (1.00) 정책협의회 (0.99)
마스크 (0.96) 제3지대 (0.94)수원컨벤션센터 (1.00) CCTV (0.84)
거리두기 (0.82) 민주주의 (0.87) 바람직 (0.99) 공동체 (0.95)
대체재 (0.98) 장례식장 (0.96) 포퓰리즘 (0.80) 일자리 (0.80)
여배우 (0.99) 취재진 (0.98) 불가능 (0.90) 글래드호텔 (1.00)
있었기 (1.00)한국사회여론연구소 (1.00) 아이들 (0.72) 경기지사 (0.73)
더불어민주당 (0.61) 재보선 (0.80) 부적절 (1.00)연합뉴스TV (1.00)
...
이렇게 추출된 명사들을 10개씩 문장으로 만들어서 mecab에 넣어서 비교를 해봤다. 정확도는 전체 개수 중 맞춘 개수이다.
# 추출된 명사를 단어만 뽑아 리스트화 시킨후
word_list=[i[0] for i in top_news]
str_dic={}
# 10개씩 나눠서 끝에 마침표를 찍어 딕셔너리에 담는다.
for n in range(0,len(word_list),10):
word_dic[n]=word_list[n:n+10]
tmp_str=' '.join(word_dic[n])
str_dic[n]=tmp_str+'.'
...
# 출력
입력텍스트(soy_nlp 명사) : ['아이들 경기지사 단일화 어떠한 리얼미터 실시간 더불어민주당 재보선 부적절 연합뉴스TV.']
출력텍스트(mecab 통과) : ['실시간', '리얼미터', '경기지사', '단일', '아이', '연합', '부적', '보선', '뉴스', '민주당']
정확도 : 0.3
맞춘명사 : ['실시간', '리얼미터', '경기지사']
없는명사 : ['아이들', '단일화', '어떠한', '더불어민주당', '재보선', '부적절', '연합뉴스TV']
코드가 좀 더럽고 길어서 다 올리긴 좀 그래서 초반부만 올렸다.. 생각보다 결과는 처참했다..
😳 결과
- 첫번째 문제점은 추출된 명사를 공백으로 이어 붙여서 완전한 문장이 아니라 그냥 명사로만 이루어진 문장이라 그런지 mecab이 제대로 인식하지 못하는 경우가 많았다. 이 부분은 mecab의 명사 추출 과정을 이해하지 못했기에 신경쓰지 못했다.
- 그리고 추출된 명사도 200개를 뽑았을 때 더불어민주당, 거리두기, 재보선과 같이 복합명사나 신조어(줄임말 등)가 보이긴 하지만, 있었기, 세금으로와 같이 이상한 결과들도 많다..
🙌 마무리
그래도 나름 하면서 재밌다고 생각했던 시도였다. 다만 생각보다 결과가 좋지 않아서 문제다... 저것만 사용해서 미등록단어를 자동으로 등록하게 한다면 결과가 좋지 않을게 뻔하다... 다음엔 우선적으로 내가 사용하는 모델의 원리에 대한 이해하는 과정을 충분히 거친 뒤, 이러한 작업을 시도하면 더 좋은 결과를 낼 수 있지 않을까 싶다. 앞으로 더 분발하자 ~~ 🔥
reference
- soynlp : https://github.com/lovit/soynlp
'python > 자연어처리' 카테고리의 다른 글
| [자연어처리 입문] 2. 언어 모델(Language Model) (0) | 2021.04.13 |
|---|---|
| [자연어 처리 입문] 1. 텍스트 전처리 (0) | 2021.04.11 |
| [Python] 한글깨짐(?)현상 정규표현식 처리 (0) | 2021.03.16 |
| [Python] Pandas를 이용하여 데이터를 다뤄보자. (0) | 2021.03.08 |
| [Python] 정규표현식 (0) | 2021.02.24 |